
MontyCloud DAY2 Automated Resource Tagging for AWS MAP
Have you signed an agreement to begin migrating to AWS? Or are you a Managed Service Provider (MSP) with an AWS Migration Competency delivering AWS...
The common misconception is that cloud applications are disaster proof. Several high-profile downtime events have proven otherwise. The reasons for downtime can range from misconfigurations to noisy neighbors. Planning and frequently testing disaster recovery plans can be complex. In this blog, Bhargava K, Cloud Solutions Engineer at MontyCloud writes how a Fortune 200 ISV, automated and simplified cross-region disaster recovery with MontyCloud’s DAY2™ Disaster Recovery Bot. So much so, that the customer is able to achieve 1 Hr. RPO and 4 Hr. RTO with a simple Slack command, as well as test their DR process on demand.
– Sabrinath S. Rao
The common misconception is that once you move to the cloud, you do not need a disaster recovery plan. Nothing can be further from the truth. Yes, the underlying cloud services are a utility and are always available. The major cloud vendors have done a great job over the years in minimizing blast radius of major events.
Application downtime can happen for a number of reasons. Several high profile downtimes in 2020 show that despite their best efforts, the cloud providers are not immune. For example, several AWS services were down on November 25, 2020 for several hours, when something as routine as a relatively small capacity addition to Amazon Kinesis service, affected other foundational services such as AWS CloudWatch.
While cloud infrastructure downtime has broad impact, fortunately they are few and far between. Most disasters are caused by factors such as domain controller failures, misconfigurations, under provisioning core services such as load balancers, noisy neighbors, and scaling errors to name a few. Organizations need to prepare for such events.
In this blog, I will discuss how one of the largest mobile workforce management applications, part of the portfolio of a fortune 200 Independent SaaS Vendors (ISV) uses MontyCloud DAY2™ to achieve 1–hour Recovery Point Objective (RPO), 4-hour Recovery Time Objectives (RTO) and on-demand recovery testing with just a slack command, across 600 hundred Amazon Elastic Compute (EC2) Instances, with an autonomous BOT based approach.
With 600 EC2 instances in production across two production regions (primary regions), it is nearly impossible to setup and monitor replication, and trigger a disaster event manually. It requires planning, as well as continuous monitoring, policy enforcement, an efficient design and frequent testing. AWS provides many tools such as CloudEndure, Amazon Elastic Block Storage (EBS) Snapshots,AWS CloudWatch (CloudWatch) Events and AWS Health (Personal Health Dashboard ).
This global ISV uses MontyCloud DAY2™ Disaster Recovery Bot (DR Bot) to orchestrate cross region disaster recovery plan. The first is between US: Northern California (primary region), and US: Oregon (disaster recovery region. And the second between Europe: Ireland (Primary) and Europe: Frankfurt (Secondary).
For the disaster recovery plan to work, the customer needs to automatically enforce the following:
The IT teams ensure that all production EC2 Instances deployed by their application teams follow these guidelines by enabling them with a pre-configured DAY2™ EC2 Blueprint.
The DAY2™ EC2 Blueprint is a no-code, guard railed, Infrastructure as Code provisioning blueprint that IT teams can enable for their applications teams through a self-service portal.
EC2 Blueprint Deployment
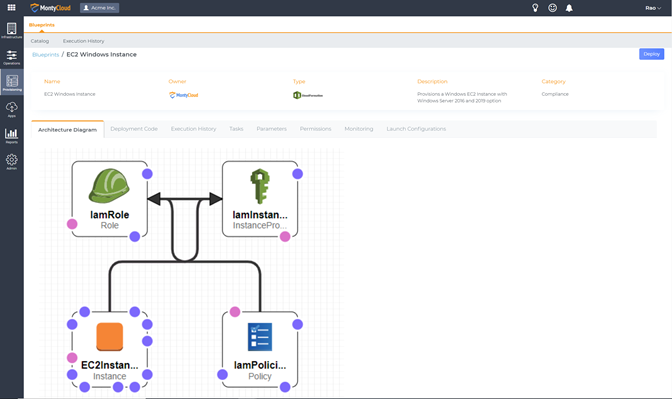
EC2 Windows Instance Architecture
The DAY2™ Disaster Recovery Bot enables the IT team to continuously monitor for outage events and orchestrate an autonomous disaster recovery across several hundreds of EC2 instances. The IT team is notified through Slack or AWS Simple Notification Service (SNS) when a recovery is complete. The DR Bot is built using native AWS services. The IT team does not have to deploy or maintain any third-party agents. The DR Bot enables IT teams to run autonomous disaster recovery and save on operations costs.
The DAY2™ Disaster Recovery Bot automates all the five elements of the disaster recovery.
Recovery is as simple as populating from AWS DynamoDB. The DR Bot has workflow rules to automate this process.
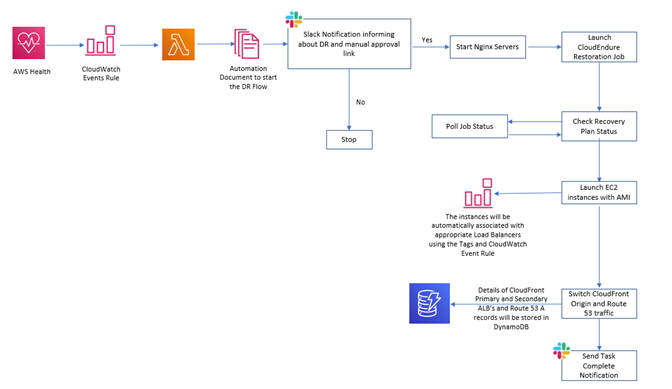
Recovery is as simple as a Slack Notification
Frequent testing ensures that disaster recovery plan works in the event of an actual event. Industry best practice is to test a failover once a quarter. However, since this customer works with enterprises with stringent requirements, demonstrating disaster recovery is part of their sales cycle. Frequently, they have to demonstrate their disaster readiness several times a day. The DAY2™ DR Bot has test mode pre-configured. At the click of a button the test process, including the slack notifications are automated.
You should use the DAY2™ Bot so you don’t have to acquire deep knowledge of tens of different AWS services, integrate and test them frequently. MontyCloud’s AWS certified engineers have built this Bot using the AWS Well-Architected Principles. All you have to do is select a configuration setting and your EC2 Instances are DR enabled. Apart from the costs of distracting your AWS experts on you staff from more valuable tasks, the DAY2™ Bot can save several months of design, build and testing time. For an environment of this scale the automation can further save you at least five high value personnel. Furthermore, the autonomous nature of the Bot ensures that your disaster recovery plan is timely and reliable.
A disaster recovery plan is critical for applications in the cloud. DAY2™ Disaster Recovery Bot can help you drive a reliable and timely recovery in the event of your primary cloud region going down. The autonomous nature of the Bot can help you scale fast, efficiently and in a cost-effective manner, saving you time and people costs.
You can get started with the DAY2™ Disaster Recovery Bot today through DAY2™ Well-Managed Servers. Start your FREE Trial today!


Have you signed an agreement to begin migrating to AWS? Or are you a Managed Service Provider (MSP) with an AWS Migration Competency delivering AWS...

The Imperative of Infrastructure as Code (IaC) Just as blueprints are vital for constructing resilient physical infrastructure, Infrastructure as...

Today I am super excited to announce the availability of MontyCloud’s CoPilot for Cloud Operations, an interactive Agent for simplifying Cloud...